Conception de l’étude et population
Cette enquête mondiale a été réalisée selon un plan transversal. Elle a été menée entre avril et juin 2024, auprès d’un groupe diversifié de chercheurs médicaux et paramédicaux ayant reçu une formation au programme GCSRT de Harvard. Ce programme est composé de chercheurs de plus de 50 pays et de 6 continents couvrant diverses spécialités, étapes de carrière, tranches d’âge et sexes. Dans le cadre du programme, tous les participants reçoivent une formation avancée à chaque étape de la recherche, y compris l’analyse statistique, la publication et la rédaction de subventions8. Ils constituent donc un groupe idéal pour évaluer l’utilisation des outils d’IA dans la recherche.
Objectifs de l’étude
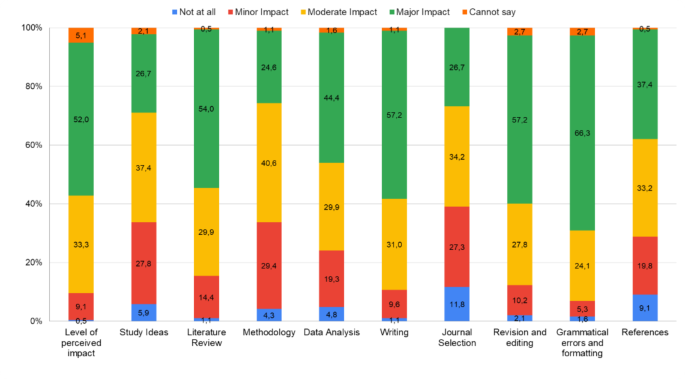
Nous avions trois objectifs principaux pour cette étude. Premièrement, évaluer le niveau de sensibilisation aux LLM parmi les chercheurs du monde entier. Deuxièmement, identifier comment les LLM sont actuellement utilisés dans la recherche universitaire et la publication parmi les répondants à notre enquête. Et troisièmement, analyser l’impact futur potentiel et les implications éthiques des outils d’IA dans la recherche et l’édition médicales.
Critères d’éligibilité
(un)
Critère d’intégration : Chercheurs médicaux et paramédicaux ayant participé au programme GCSRT à HMS appartenant à n’importe quelle cohorte entre 2020 et 2024, quels que soient leur pays d’origine, leurs intérêts de recherche, leurs années d’activité dans la recherche, leur âge ou leur sexe. Les chercheurs qui étaient membres des groupes WhatsApp non officiels de la classe et maîtrisaient la lecture et l’écriture en anglais ont été spécifiquement inclus.
(b)
Critère d’exclusion : Les chercheurs issus de cohortes en dehors des années spécifiées ci-dessus, ceux qui n’étaient pas accessibles via les groupes WhatsApp en classe ou qui ne maîtrisaient pas la lecture et l’écriture en anglais ont été exclus de l’étude. Les chercheurs médicaux et paramédicaux n’ayant pas suivi de formation dans ce programme ainsi que les chercheurs non médicaux n’ont pas été invités à cette étude.
Stratégie d’élaboration du questionnaire et de diffusion de l’enquête
L’enquête a été rédigée à l’aide de Google Forms, en langue anglaise. Il comprenait un total de 4 sections pour couvrir nos principaux objectifs : (1) Contexte, (2) Sensibilisation aux LLM, (3) Impact des LLM et (4) Politique future. Chaque question a été soigneusement examinée pour sa pertinence, sa validité et son impartialité. Les collecteurs de données pour l’étude ont été volontairement choisis parmi les participants du programme GCSRT. Les collecteurs de données de chacune des cohortes ciblées ont été chargés principalement d’atteindre notre population cible dans leur cohorte via la messagerie personnelle sur WhatsApp et LinkedIn. Les coordonnées des personnes interrogées ont été obtenues à partir des groupes WhatsApp non officiels et des réseaux personnels des collecteurs de données. Au total, 3 messages personnels comprenant 2 rappels, espacés de 7 jours chacun, ont été envoyés à chaque participant potentiel. Un consentement éclairé a été obtenu et des formulaires d’enquête Google ont été remplis par un total de 226 chercheurs provenant de plus de 59 pays.
Taille de l’échantillon et méthodes statistiques
Le lien vers le formulaire d’enquête Google a été distribué à 5 cohortes du programme GCSRT composées d’un total de 550 chercheurs médicaux et paramédicaux. Un échantillon total de 220 personnes a été calculé en considérant une marge d’erreur de 5 %, un niveau de confiance de 95 % et une puissance de 0,8. Les statistiques descriptives des répondants à l’enquête ont été présentées sous forme de moyenne ± écart type pour les données continues normalement distribuées, médiane (intervalle interquartile) pour les données continues non normalement distribuées, et fréquences et pourcentages pour les données catégorielles. La normalité des données continues a été testée à l’aide du test de Shapiro – Wilk. Les données normalement distribuées ont été analysées à l’aide d’une ANOVA unidirectionnelle, tandis que les données non normalement distribuées ont été analysées à l’aide du test de Kruskal-Wallis. Les données catégorielles ont été analysées avec le test du Chi carré ou le test exact de Fisher. Les données qualitatives issues de questions ouvertes ont été étudiées via une analyse thématique. Toutes les analyses statistiques ont été effectuées dans Stata MP version 17.0 (StataCorp, College Station, TX, USA). Tous les tests étaient bilatéraux et considérés comme significatifs à P.
Considération éthique
Conformément à la déclaration d’Helsinki8, cette étude a été approuvée par le comité d’examen éthique du Allama Iqbal Medical College/Jinnah Hospital Lahore, Pakistan (numéro de référence : ERB 163/9/30-04-2024/S1 ERB). Il n’est ni pris en charge ni approuvé par HMS. Cependant, une notification opportune concernant l’étude a été fournie à l’administration du programme GCSRT. Le consentement à participer a été recueilli auprès de chaque répondant comme première réponse obligatoire au questionnaire. Toutes les informations personnelles telles que l’identifiant de messagerie, la nationalité et l’âge ont été soigneusement anonymisées et traitées de manière confidentielle. Les répondants ont reçu les informations nécessaires sur le caractère volontaire de l’étude ainsi que les coordonnées du chercheur principal.
#Utilisation #grands #modèles #langage #comme #outils #dintelligence #artificielle #dans #recherche #universitaire #publication #parmi #les #chercheurs #cliniques #mondiaux